
Announcing The CUIP 2019 Smart City Data Challenge
Authors: Dr. Mina Sartipi, Josh Patterson, James Long, Austin Harris, Jose Stovall
Date: August 27th, 2019
This year the Center for Urban Informatics and Progress (CUIP) program is putting on its second annual data science conference (link to 2018 conference). This year the 2019 CUIP conference is focused on analysis of smart city data and is also putting on a data modeling competition that ties into the conference focus with the theme:
"Predicting Urban Air Pollution Levels From Weather Data and Street Video Events"
Video: Example object detection (YOLO v2) video footage
from Broad Street in Chattanooga
The CUIP program has been steadily building out its smart city platform for data collection at the pole and wide scale data ingest into a data lake. Dr. Sartipi and UTC decided to release a portion of the CUIP data collected from the testbed to further engage the research community on the fruits of the data collection. To support the focus of the conference the data release is kicked off with the CUIP 2019 Smart City Data Challenge for anyone and everyone to participate.
Patterson Consulting (as a CUIP supporter) has been involved in advising on the infrastructure architecture and data science practices for the CUIP Smart City Platform. This year Patterson Consulting also helped design of the CUIP Smart City Data Challenge. This support falls in line with Patterson Consulting's long term support of regional research output and its correlation with regional economic growth and development.
What is the Data Challenge?
The 2019 Smart City Data Challenge is focused on predicting PM2.5 levels in the air from the recently open sourced CUIP 2019 Challenge Dataset. The CUIP program is interested in multiple domains related to smart city analytics, but this year they are focused specifically on how smart city's can be improved with sensor deployment across the city. One of the first applications of this sensor deployment is understanding how traffic can affect quality of life in a city, specifically traffic's impact on people's health.
The concept of the CUIP Dataset is largely drawn from the purpose and success of the ImageNet dataset. Machine learning research in any domain cannot move forward without good open datasets, no matter how exotic the applied machine learning methods are. To drive smart city application research forward it was concluded that the CUIP program needed to be a leader in building quality smart city datasets. Just like with the ImageNet dataset, the CUIP research group built a dataset and then created a competition and conference to get like-minded researchers in the same room to talk about the problem space.
For this data challenge we're looking to predict PM2.5 levels each day based on cars passing through the smart city corridor and local weather from the sensor stations in the corridor. If we can build a model to predict pollution levels at the intersection-level in an urban environment, we can build potentially build a more detailed pollution map of urban areas and better understand how our cities work. This contest is unique in how we're using both weather data and urban street level object detection data combined to predict pm2.5 levels where most competitions so far have used only weather data.
Similar Competitions
In recent years there have been similar competitions predicting pm2.5 levels from previous hours/days of weather data. Kaggle ran a competition in 2018 for predicting pm2.5 values based on weather in Chinese cities. Also in 2018 we saw the ACM SIG KDD competition focused on predicting "the PM2.5, PM10, and O3 concentration levels over the coming 48 hours for every measurement station in Beijing".
What is pm2.5?
PM2.5 is short hand for any atmospheric particulate matter (PM) that has a diameter of less than 2.5 micrometers. For reference this matter is about 3% the diameter of a human hair.Why is pm2.5 Dangerous in our Cities?
Studies in large cities have shown to be associated with respiratory system disease in humans.
From Wikipedia:
Further:“In 2013, a study involving 312,944 people in nine European countries revealed that there was no safe level of particulates and that for every increase of 10 μg/m3 in PM10, the lung cancer rate rose 22%. The smaller PM2.5 were particularly deadly, with a 36% increase in lung cancer per 10 μg/m3 as it can penetrate deeper into the lungs.[11] Worldwide exposure to PM2.5 contributed to 4.1 million deaths from heart disease and stroke, lung cancer, chronic lung disease, and respiratory infections in 2016.”
It stands to reason that better understanding air pollution beyond the granularity of the city-level has value to the citizens and government of any city.“Traffic congestion increases vehicle emissions and degrades ambient air quality, and recent studies have shown excess morbidity and mortality for drivers, commuters and individuals living near major roadways. Presently, our understanding of the air pollution impacts from congestion on roads is very limited. ”
Where does pm2.5 come from?
There are some natural sources of pm2.5 levels such as forest fires, agricultural burning, volcanic eruptions and dust storms. Our focus here is how a city can be impacted by human sources of pm2.5. These human-based sources include
- power plants
- motor vehicles
- airplanes
- residential wood burning
- construction sites
The CUIP Smart City Data Challenge Dataset

The intial idea for the dataset release was to provide researchers an easy way to work with smart city data such that they could experiment and come up with novel applications. Bringing software into the CUIP platform, while possible, is not as simple as "just working with data". From that perspective, we wanted to give the data community some data so they could get something to work with in their own time and potentially reference the data in their own research.
The best exemplar we had was how ImageNet (coupled with the rise of GPUs) helped drive huge gains in model accuracy for computer vision research. This gave us the idea of creating an "ImageNet for Smart City", and this is how the CUIP Smart City Dataset was born.
The base hypothesis was that early analysis showed pm2.5 levels on the street correlated over time with vechicles passing through the street. However, there were other factors in play such as:
- weather
- type of vehicle
- construction around the sensor pole
- time of day
Just like with understanding how cars move through an intersection can make traffic operations more efficient, we can better design and operate cities when we understand how pollution affects sections of our city. As car usage has increased in over-subscribed urban areas, we see their emissions significantly rise in relative contribution to city pollution. As cities become more complex with the rise of global population it is critical to measure and understand all aspects of how we operate cities.
This competition is based around further exploring how the main independent variable (vehicle object counts from video frame analysis) along with weather data can more accurately predict the pm2.5 levels during the day.
This is a compelling use of video frame detected objects becasue it potentially makes it far simpler to build fine-grained pollition maps of cities.
Going Beyond Just Cleaning Up the City
Finally, we'll note how the city has come full circle from being named infamously by Walter Cronkite as "America's Dirtiest City" on the evening news. To be fair, he wasn't wrong as the lead paragraph from the March 4, 1969 Chattanooga Times read:
"Chattanooga's particulate air pollution is ranked the worst in the nation for the period of 1961-65 in an 1,800-page publication on Air Quality Criteria for Particulate Matter just released by the Department of Health, Education and Welfare."
It's an inspiring story to see the city once labeled as the nation's dirtiest transform itself into being a city that is on the forefront of building next-generation smart city pollution maps.
Dataset Structure
The CUIP Smart City Dataset is divided into two major parts:
- Daily air quality data
- Object detections from video frames
The air quality data is collected from the Purple Air Sensor located at each intersection along the smart corridor. Each reading includes columns such as humidity and temperature. It also has the PM2.5 level for the same point in time along with other particulate types. Take a look at the dataset website to see all of the columns.
Releasing the dataset involved a few challenges, namely the limitation that CUIP was not allowed to release image data from any of the cameras on the smart corridor. With that restriction in mind, the CUIP program used open source computer vision models to produce object detections on the data and then save only the detected objects in their data lake internally.
The object detection data is in the other main directory in the dataset and contains daily object detections as they occured per intersection. The object detection data was more complex to release due to limitations around what information could be released. The CUIP program could not release the video data itself, so instead they decided to release the detected objects from the video frames. These object detections were produced with the YOLOv2 Convolutional Neural Network computer vision model along with some custom scene object tracking code developed by the CUIP program.
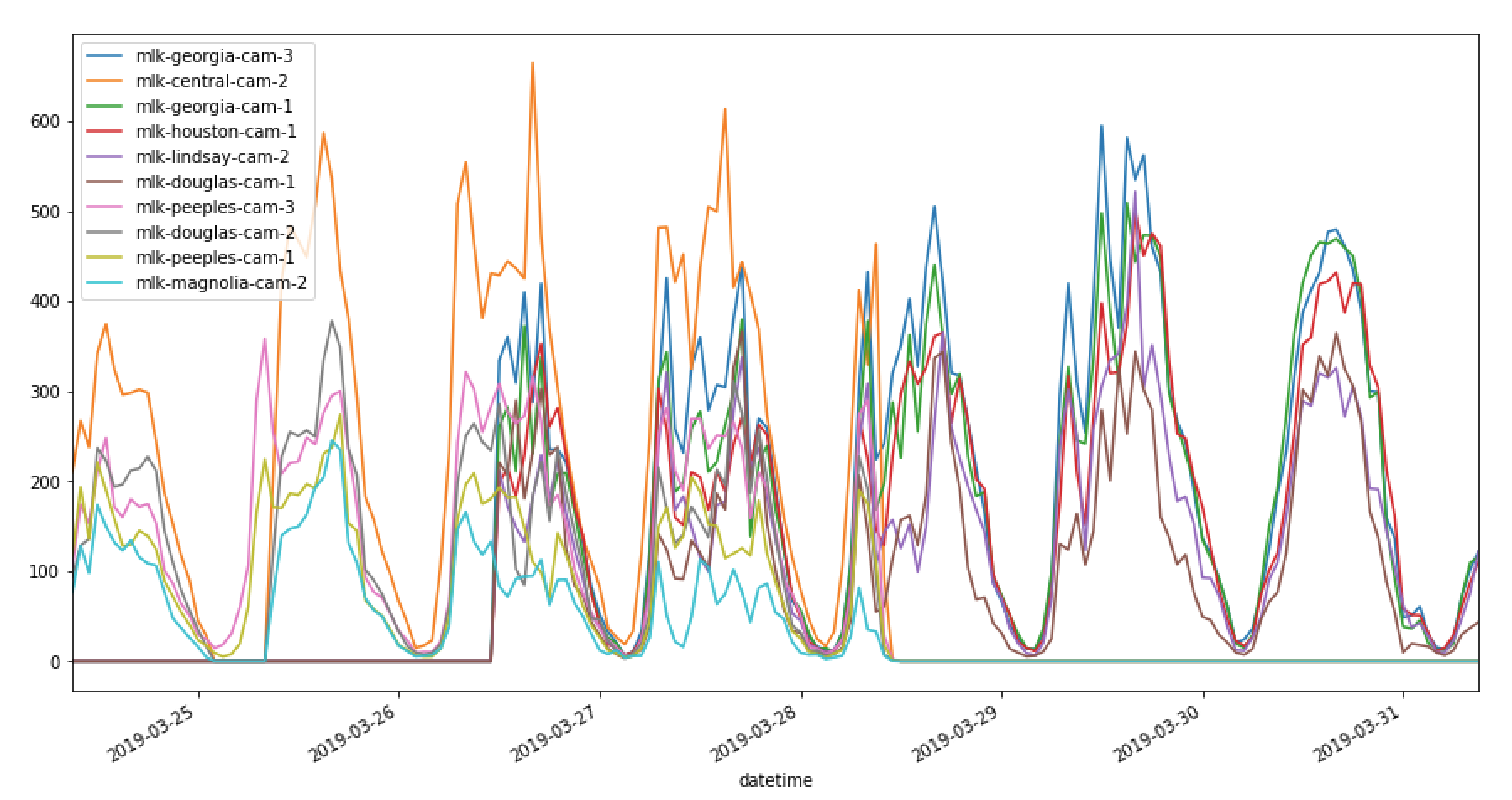
Graphed sample of object detection data per hour at each intersection.
We'll note that the YOLOv2 model has its tradoffs but coupled with the object tracking methods developed by the CUIP program it was able to achieve good accuracy. Given that the YOLOv2 object detections are consistently effective across all frames in all intersections, any missed detections or duplicated detections should normalize out in the input data normalization/standardization/vectorization process. Beyond these disclaimers, we'll also note that this is real-life data and a seasoned practitioner will realize that many times we must deal with data that needs to be cleaned up.
We consider having to deal with complex data to be part of the competition and we look forward to hearing the methods used by the top 3 teams during the conference on the winners panel.
Competition Rules
This contest is based around “Predicting Urban Pollution Levels From Street Video Events and Weather”.
The specific goal of the contest is to use 3 weeks of CUIP basic weather information and object detections to build a model to predict the pm2.5 level for each hour (top of hour) in a day (7am-7pm, top of the hour) for every intersection across 5 days.
Training Data
The training data will consist of 3 weeks of CUIP collected data containing:
- air quality (weather + purple air particulate matter readings)
- vehicle object detections
We show the air quality csv data header below:
,current_dewpoint_f,current_humidity,current_temp_f,lat,lon,p_0_3_um,p_0_3_um_b,p_0_5_um,p_0_5_um_b,p_10_0_um,p_10_0_um_b,p_1_0_um,p_1_0_um_b,p_2_5_um,p_2_5_um_b,p_5_0_um,p_5_0_um_b,pm10_0_atm,pm10_0_atm_b,pm10_0_cf_1,pm10_0_cf_1_b,pm1_0_atm,pm1_0_atm_b,pm1_0_cf_1,pm1_0_cf_1_b,pm2_5_atm,pm2_5_atm_b,pm2_5_cf_1,pm2_5_cf_1_b,timestamp,nicename,SensorId,Adc,response_date,key2_response_b,wlstate,pm2.5_aqi,ts_s_latency_b,DateTime,httpsuccess,key2_count_b,key2_response_date_b,period,hardwareversion,httpsends,memcs,pressure,key2_response,version,Geo,status_6,status_5,status_8,key1_response,status_7,Mem,pm2.5_aqi_color,status_9,key1_count,ts_latency_b,key1_response_date,status_0,Id,status_2,status_1,status_4,status_3,pm2.5_aqi_b,loggingrate,latency,key1_count_b,memfrag,key1_response_b,key2_count,hardwarediscovered,place,rssi,key2_response_date,pm2.5_aqi_color_b,pa_latency,key1_response_date_b,uptime,ts_latency,ts_s_latency,response,location,memfb,timestamp-iso,status_10,response_b,response_date_b,latency_b
And then a sample air quality csv record:
0,54,26,95,35.039406,-85.291992,2386.27,2242.46,730.58,711.25,0.33,0.0,144.39,133.76,9.8,3.36,2.23,0.67,23.61,19.76,23.61,19.76,13.08,13.56,13.08,13.56,22.21,19.4,22.21,19.4,1559406002000.0,mlk-central,84:f3:eb:44:d8:24,0.04,1559405882.0,200.0,Connected,72.0,731.0,2019/06/01T16:20:02z,4470.0,119148.0,1559406002.0,120.0,2.0,4470.0,1024.0,988.47,200.0,4.02,PurpleAir-d824,1.0,2.0,2.0,200.0,0.0,19128.0,"rgb(255,244,0)",2.0,108612.0,739.0,1559405999.0,2.0,1482.0,2.0,2.0,2.0,2.0,66.0,15.0,52.0,119212.0,22.0,200.0,117694.0,2.0+OPENLOG+15931 MB+DS3231+BME280+PMSX003-B+PMSX003-A,outside,-65.0,1559406000.0,"rgb(255,251,0)",560.0,1559406001.0,88926.0,845.0,728.0,200.0,"35.039406, -85.291992",14840.0,2019-06-01 16:20:02,,,,
Note that there are multiple columns that represent pollution measurements from the Purple Air sensor.
p_0_3_um,
p_0_3_um_b,
p_0_5_um,
p_0_5_um_b,
p_10_0_um,
p_10_0_um_b,
p_1_0_um,
p_1_0_um_b,
p_2_5_um,
p_2_5_um_b,
p_5_0_um,
p_5_0_um_b,
pm10_0_atm,
pm10_0_atm_b,
pm10_0_cf_1,
pm10_0_cf_1_b,
pm1_0_atm,
pm1_0_atm_b,
pm1_0_cf_1,
pm1_0_cf_1_b,
pm2_5_atm,
pm2_5_atm_b,
pm2_5_cf_1,
pm2_5_cf_1_b
Specifically for this competition we're going to use the column "pm2_5_cf_1" in the air quality data as the dependent variable for the model (in the purple air instructions they indicate this by saying "PM2.5 (CF=1) ug/m3 This is the field to use for PM2.5"). In your regression model you should be using the value of this column as your output/label. To better understand the meanings of the columns in the air quality data, check out this gdoc from Purple Air with schema information.
Why are there "a" and "b" channels for each pm-variable?
“PurpleAir sensors employ a dual laser counter to provide some level of data integrity. This is intended to provide a way of determining sensor health and fault detection. Some examples of what can go wrong with a laser counter are a fan failure, insects or other debris inside the device or just a layer of dust from long term exposure. If both laser counters (channels) are in agreement, the data can be seen as excellent quality. If there are different readings from the two channels, there may be a fault with one or both.”
Held Out Prediction Data
The held out data for the prediction task will contain data for the dates June 25th - 29th:
- weather (no particulate matter information)
- vehicle object detections
Prediction Goal
The goal is to predict the missing pm2_5_cf_1 column for the days of June 25, 26, 27, 28, and 29. This means the contestant will need to make predictions for pm2_5_cf_1 across 5 days during 12 hours each day (top of the hour) for 7 different interestions
The prediction output CSV file will contain a line for all combinations of 7 intersections from 7am-7pm (12 hours) on the top of the hour for 5 days. This will give us a CSV submission file of (7 x 12 x 5 ==) 420 different lines of pm2_5_cf_1 predictions.
The intersection IDs to predict are:
mlk-central
mlk-douglas
mlk-georgia
mlk-houston
mlk-lindsay
mlk-magnolia
mlk-peeples
Contestants should list out the full string intersection ID in their submission CSV file.
Submitting an Entry
Teams can submit multiple times to the competition. Each submission will consist of a CSV file in the format:
date,time_hour,intersection_index,pm2_5_value
2019-06-25,7:00,mlk-douglas,100.0
2019-06-25,8:00,mlk-douglas,100.0
2019-06-25,9:00,mlk-douglas,100.0
2019-06-25,10:00,mlk-douglas,100.0
2019-06-25,11:00,mlk-douglas,100.0
...
Each team will save their entry in the above CSV file format and email it to cuip-cscdc@utc.edu for leaderboard processing. If your team has questions, you can also use the same email address for any questions about the competition.
Evaluation Method
The evaluation metric will be Mean Square Error (MSE) across all predictions.
A leaderboard will list the top 5 entries / teams and will be updated twice a week (Tuesdays and Fridays) leading up to the conference.
Top 5 teams will have to send in model for confirmation once the competitions has ended.
Contest Deadlines
The deadline for model submission: Sept 6th, 2019.
Contest Winners and Competitors at the 2019 CUIP Conference
All teams who participate are invited to present a poster for their methods at the 2019 CUIP conference in Chattanooga, TN during the poster session of the conference.
The top 3 teams will be invited to be on the panel during the conference to discuss the dataset and their techniques for getting the best results.
Brief Overview of the CUIP Platform Architecture
The CUIP platform has stations along intersections down M.L.King Blvd in downtown Chattanooga, TN, as shown in the image below.
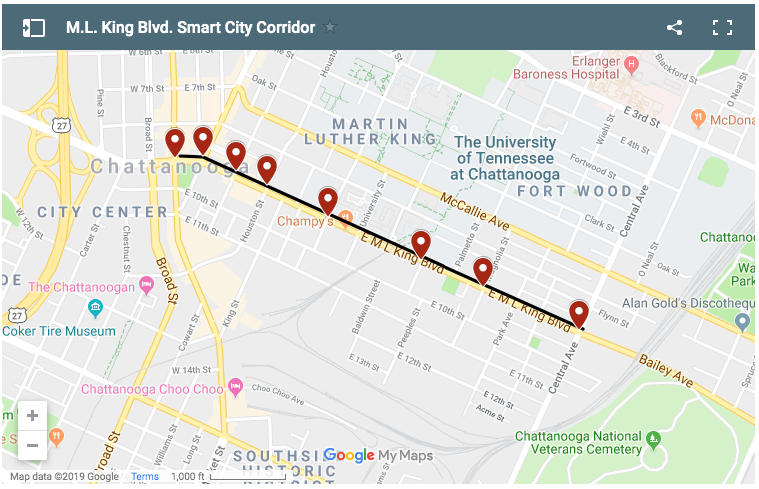
Each intersection sensor groups has:
- cameras
- LIDAR
- RADAR
- microphones
- python and pandas
- GPUs and TensorFlow
- Kubernetes and Kubeflow
R and Python Code to Get You Started
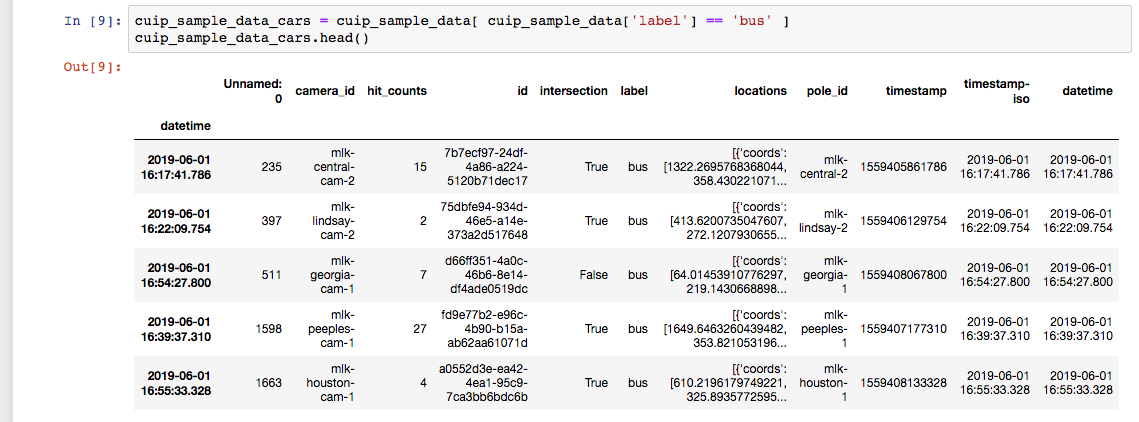
Some of the seasoned data scientists out there may jump right in and start downloading data to analyze with their favorite tools and methods. However, for our newer data scientist friends, we wanted to provide some sample data and an example notebook (hosted on Github) on how to work with the data in python with pandas. We hope this allows people who just want to learn more about the CUIP dataset challenge an easier way to work with the data in a friendly Jupyter notebook environment. In the image below we can see some operations being performed on the sample object detection data from the dataset.
 And then an R-based notebook example from James Long:
And then an R-based notebook example from James Long:
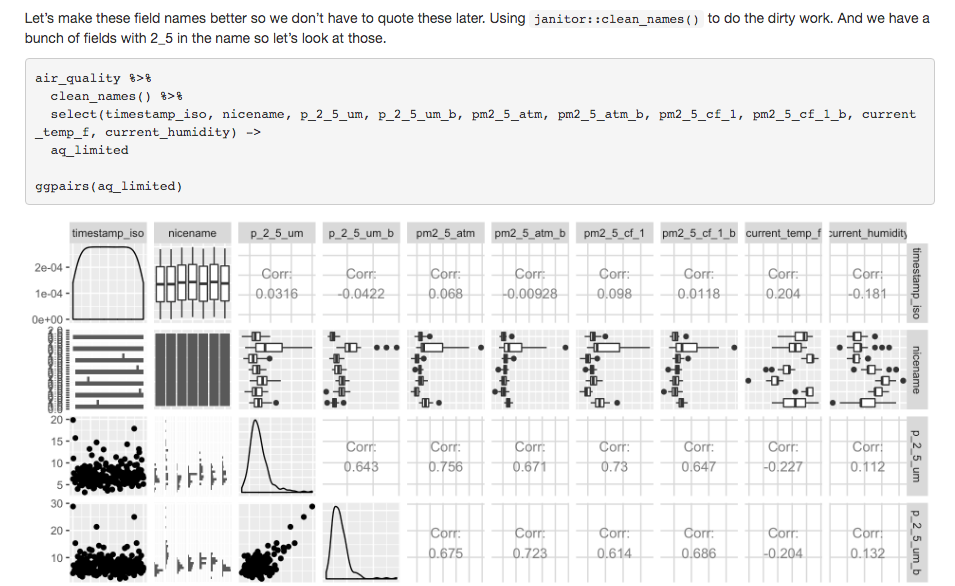
List of Example Notebooks
List of pre-built notebooks to use the data:
- James Long (of R Cookbook fame) provided an R-based notebook for the competition
- Basic data loading python notebook from our github account
Even if you don't participate in the competition, it might be fun to play around with the data and see what you can learn about how traffic moves through MLK street in Chattanooge. We'd love to hear your stories at the competition at the coffee or poster sessions.
See You at the 2019 CUIP Smart City Conference
Map to the Edney Center.
Good luck to all participants in the 2019 CUIP Smart City Data Challenge. Come check out the winning team's methods at the 2019 CUIP Deep Learning Conference in Chattanooga, TN at the Edney Center on September 13th, 2019. Be sure to catch talks at the conference by companies such as:
- The Google Cloud Team
- Nvidia
- Ford