
Building the Next-Gen Retail Experience with Apache Kafka and Computer Vision
Part 2 of 4
Authors: Josh Patterson, Stuart Eudaly, Austin Harris
Date: October 31st, 2019
In our last blog post, we saw a new business plan developed by Big Cloud Dealz to update their in-store retail experience. In this post, we'll look at the object detection portion of that plan, along with sending those detected objects to Kafka.
Prototyping Shopping Cart 2.0 with Computer Vision
Demonstration of object detection. Object detection in computer vision is defined as finding objects in images with “0 to multiple objects per image.” Each object prediction is accompanied by a bounding box and a class probability distribution.
The team has stated they need to do some computer vision on the contents of the cart, but they don't have the resources to get too exotic. They've read a lot about object detection lately in the domain of computer vision and they know there are a lot of pre-trained models available for TensorFlow. After watching several demos and videos of applied object detection models, they decide on leveraging one of the models provided in the TensorFlow object detection project.
They need to know what's happening in real-time in those shopping carts, but can't spend a ton of time developing the cart sensor because management wants to see a working prototype "soon." The data science team ran some tests on available pre-trained models and observed that the shopping cart bottoms have an odd pattern that tends to disrupt certain item's classifications with the model.
The SVP of Application Development doesn't want to spend on a custom model (yet). They aren't sure of the value of collecting a lot of custom shopping cart image data, and they want to see what stock models can do first. If they can get a basic model working to show "something," they will likely get the green light to iteratively improve Shopping Cart 2.0 with more custom models based on the earlier models.
Refining Models for Specific Use Cases with Transfer Learning
Stock models can work well out of the gate as we'll see through the progression of this blog article. However, many use cases require a certain level of accuracy on a task to be relevant from a business standpoint (e.g., "we have to be able to detect N% of objects in a shopping basket before the upsell makes us money"). The background of the shopping basket and the specific inventory shapes tend to mess with the object detection system somtimes and would need to be accounted for in the model.
Transfer learning has a few variants, but the classic case is where we take an existing convolutional neural network from a model repository such as the TensorFlow model zoo and further train it with domain-specific data. More specifically:
"In this variant of transfer learning, we see a CNN model trained on a large data‐ set such as ImageNet, and then we replace the last “classifier layer” with some‐ thing specific to the fine-tuning dataset. Some variants will continue to perform backpropagation on all of the layers, and others will update only the later layers. This is because many of the earlier-layer features are general to all types of vision processing and there is less need to update them. The later layers are focused on combining these lower-level features in task-specific ways and are more relevant to train on the domain-specific dataset." Oreilly's "Deep Learning: A Practitioner's Approach", Patterson / Gibson 2017
Another great reason to use transfer learning is because models quickly "age" as the distribution of the image data shifts. This means, as the inventory in the store (for example) gets updated, the model will be less effective at detecting specific objects in the basket as some inventory items will be knew and then some inventory items will get dropped. We need a way to keep our model "fresh" and will likely have to periodically rebuild the model (or have someone do it for us with a managed model service). Managing model versions also becomes an issue as we begin to rotate new versions of models into / out of production. This topic is addressed in the sidebar at the end of this article.
For the purposes of building this sample application we aren't going to fine tune the shopping cart computer vision model. In a future article beyond this 4 part series, the Patterson Consulting team will show examples of transfer learning in action for a specific domain. An existing example of transfer learning in action is the TensorFlow pet detector example.
Selecting an Initial Object Detection Model

R-CNN pre-trained model output rendered on input image of a ball and two frisbees with bounding boxes and classifications.
Given that they need an Android device on the cart itself to collect images of the basket items, it makes sense that they run the model "at the edge" on the cart Android device, and only send the model predictions. Model predictions are produced through a process known as "inference" where input data is taken and does a forward pass through the network. The output layer gives the prediction, and that's the output that will be sent on to the rest of the application. Another advantage of doing inference on the Android devices is that it allows leverage of all of the CPUs in the fleet of Shopping Cart 2.0s, as opposed to having to use a bank of GPUs back in the data warehouse.
To summarize the process:
- Periodically take a picture of the contents of the basket.
- Use the picture as input to the local model and get the output of the inference as the object detections.
- Pass each detected object (name of items, bounding box coordinates) to the Kafka system via the Producer API for real-time processing.
Given that their mandate is to use off-the-shelf components as much as possible to rapidly prototype, they're going to work with a pre-trained model from the TensorFlow model zoo. TensorFlow has a lot of community traction and support, so the team wants to try and leverage one of the object detection models offered from their website. The team has found some ARM9 boards (that will run TensorFlow on Android with WIFI connectivity) with cameras for under $150, so creating 100 Shopping Cart 2.0 prototypes loaded up with an object deteciton model should cost around $15k for hardware. Another advantage is that TensorFlow has JVM bindings that run on Android as well, which can be integrated with the JVM code from Kafka.
The team scans the TensorFlow model zoo and reads up on mAP scores as an overall indication of model quality. (Resources on Understanding object detection and mAP scores, and understanding speed/accuracy trade-offs in object detection.) Inference speed is generally a concern, but given that this was a prototype and the team was more interested in better mAP scores, it was less of a concern here. The application did not need to produce a lot of inferences, so a few seconds of latency between taking the picture and sending object detections back to the Kafka cluster was not a big deal.
The team chooses the COCO-pretrained Faster R-CNN with Resnet-101 model because of its general mAP accuracy and decent file size. They gave a lot of consideration to the YOLOv2 model variant, but ended up going for another model that was slower but gave a better mAP score for the application (which makes a lot of difference when we're using a stock model for prototyping). The data scientists are relieved to know that there are resources for easily training a future custom model on specific basket images (Example: training a pet detector based on Faster R-CNN Resnet 101) once they get the prototype system running for management.
With the base system design in place, the team can move on to getting JVM code working. The code needs to take a custom image as input and produce a raw inference output that can be passed to the Kafka Producer API, as we see in the next section.
Object Detection Model Inference at the Edge with TensorFlow
In this section, we'll focus on getting TensorFlow setup with Java code, the model loaded, and inferences produced from the model to send to the Kafka cluster. The core java classes for this object detection system running on each cart are listed below:
- TFVision_ObjectDetection.java: code to run the model inference with TensorFlow
- TFModelUtils.java: support utilities for TensorFlow
- VisualObject.java: class to represent detected objects from model inference output
- ObjectDetectionProducer.java: code tying the TensorFlow code into the Kafka producer API
We can see the Confluent dependencies that will support the Kafka Producer API operations along with the TensorFlow dependencies needed to load a pre-trained model (component versions are in the variables section of the pom.xml file; specifically we're using TensorFlow 1.8 in this example).
Let's take a closer look at how we'll load the TensorFlow model and make inferences in Java with the TensorFlow R-CNN object detection model. In the code section below, we can see the scanAllFilesInDirectory(...) method highlighted which performs the bulk of the work in the class.
The scanImageForObjects(...) method takes 3 parameters:
- modelFile: the TensorFlow object detection model to load for inference
- labelMapFile: list of labels the associated modelFile can output (i.e. "the vocabulary of labels the saved model understands")
- inputImageFile: the image file path that we want to use as input to the modelFile to get object detections as output from
SavedModelBundle and produce inference output on an arbitrary TensorFlow model.
We'll point out a few key areas in the TensorFlow code above:- Working with
SavedModelBundle, frozen graphs, and .pb files - TFModelUtils.java
- Converting TensorFlow output into VisualObject class instances
SavedModelBundle is handy because it contains all of the needed files to run a TensorFlow object detection model.
The TFModelUtils.java class is of note because it wraps functionality for doing things like loading label files and converting the image file input into the proper vectorized Tensor<UInt8> format.
After we get the output of the scores, classes, and bounding boxes from the TensorFlow inference output, the code converts these into a VisualObject class wrapper to make them easier to work with.
Now that we've located the VisualObjects in our basket and given them classifications, let's move on to how we'll send the classified objects to the Kafka cluster for processing.
Integrating Shopping Cart 2.0 Detected Objects into an Apache Kafka Producer
To write data to a Kafka topic we need to use the Kafka Producer API. Apache Kafka is a JVM-based system so that makes it a relatively simple process to tie the object detection code into the code using the Producer API. In this example, we can see this happening in the ObjectDetectionProducer.java class. We can see the code for this class highlighted below.
We'll highlight a few key areas of the code:
- Specifying a Kafka topic to send messages to
- Configuring the producer to use the Avro GenericRecord API
- Laying out an Avro schema for the GenericRecord API to use
- Configuring the producer properties
- Scanning all image files in a directory
- Watching a directory for incoming files
- Main run loop of the producer
scanImageForObjects(...) method produces object detections which are then sent to the configured Kafka topic shopping_cart_objects. If we update our general architecture diagram from above it now looks like:
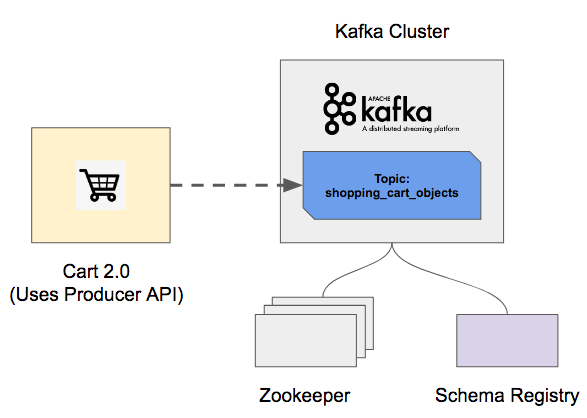
We've configured this example to use the GenericRecord Avro API and the code contains an embedded Avro schema so that we can leverage the GenericRecord API as we're prototyping this application at this stage (for more details on how to use the Generic and SpecificRecord Avro API, check out our blog post on Using Apache Avro with Apache Kafka). We also include the address of the Confluent Schema Registry so the schema can be archived in its central Avro schema repository.
For demo purposes, this producer will come alive and then scan the image files in the directory we specify on the command line when we run the ObjectDetectionProducer.java class. We include a set of pictures of items in shopping baskets for this demo, and we'll point the ObjectDetectionProducer class at the directory that contains this photos to run this demo. Additionally, we have provided a TestDetectionProducer.java class that randomly generates items every 15 seconds. This allows testing where items are continuously produced, rather than needing to have a photo for each item.
Let's Try Out The Cart Cam Application Locally
We have a Big Cloud Dealz github repository setup for trying out the code. The main dependencies you will need to run this code is the project repository from github and the model from the TensorFlow ObjectDetection Model Zoo (download the Faster RCNN ResNet 101 model file locally from this link on the TensorFlow github repository).
In the command list below, we can see:
- We need to change into the CartCamApp subdirectory inside the main repository local directory
- We need to build the project with
mvn package - We finally need to run the application itself with the
mvn exec:java ...command
/Users/josh/Downloads/ and uncompressed, so the saved_model/ subdirectory is available for our code to read.
We don't need to worry about getting images to process as those are included in the repository at ./src/main/resources/cart_images already as part of the project.
git clone https://github.com/pattersonconsulting/BigCloudDealz_GreenLightSpecial.git
cd BigCloudDealz_GreenLightSpecial
cd CartCamApp
mvn package
mvn exec:java -Dexec.mainClass="com.pattersonconsultingtn.kafka.examples.tf_object_detection.ObjectDetectionProducer" \
-Dexec.args="/Users/josh/Downloads/faster_rcnn_resnet101_coco_2018_01_28/saved_model/"
After lots of startup console output from TensorFlow, you'll see the code taking each image and scanning it from objects as shown in the console output below:
Given we're just running the TensorFlow object detection code and we haven't setup Kafka yet, the code won't actually send the detected objects to Kafka. We'll see this part of the code in action in parts 3 and 4 where we turn on Kafka and then have the CartCampApp actually write to a topic via the Kafka producer API.
AT THE END OF EVERYDAY, BEFORE I HIT THE SACK, I LOOK AT MYSELF IN THE MIRROR AND ASK MYSELF: "DID WE BRING THE WOOOOOO TODAY?"
— BigCloudRon (@BigCloudRon1) August 9, 2018
ALSO: I ENJOY STARING GREATNESS IN THE FACE.
Summary
In part 2 of this series on re-inventing the shopping cart we walked the reader through:
- Selecting an object detection model
- Integrating the model to serve predictions
- Wiring the predictings into Kafka with the Producer API
More Notes on Model Integration and Model Lifecycle Management
Obviously for this example we're hard-wiring a model into the Shopping Cart 2.0 project in a way that's great for proof of concepts, yet doesn't address many of the production lifecycle issues that arise.
Some of these considerations include:
One great reason to not send images back to the data lake is that we might capture customer-sensitive images which could cause legal issues in certain scenarios. Another reason for not capturing the images is from a pure resource standpoint. It would require more storage and processing resources be used to move the images around.
The R-CNN model the team uses in this example is good to prove to management that this concept "works," yet has a limited initial vocabulary of objects it can recognize. A real production version of this model would need to fine tune against the full inventory of the retail chain and would require retraining every time the store carried a new item. A re-train event would need to be done in a batch setting back on the data lake (probably leveraging GPUs).
Once we have a new re-trained model, we'll need to be able to deploy the model to system. We have two options: we either deploy it each night after the store closes, or we do it while people are shopping and using the system. We feel the best approach in terms of model management long term, is to leverage a model server system so the support / Ops team can treat each model as it would a RDBMS table. There are several variants of model servers today. Here are a few notable ones:
For the purposes of brevity and practicality in this example, we will not integrate a model server and will leave that as an exercise for the reader to explore later. For a further discussion on architecture ideas around machine learning infrastructure, please reach out to the Patterson Consulting team. We'd love to talk with your team about topics such as: