
Applied Machine Learning Quarterly (Q2 2020)
Author: Josh Patterson
This is an ongoing curated list of interesting new open source machine learning models, tools, and visualizations for 2020. Updated roughly quarterly.
May 2020
Tools and Infrastructure
KFServing (Kubeflow 1.0)
KFServing was designed so that model serving could be operated in a standardized way across frameworks right out-of-the-box. There was a need for a model serving system, that could easily run on existing Kubernetes and Istio stacks and also provide model explainability, inference graph operations, and other model management functions. Kubeflow needed a way to allow both data scientists and DevOps / MLOps teams to collaborate from model production to modern production model deployment.
KFServing’s core value can be expressed as:
- helps standardizing model serving across orgs w unified data plane and pre-built model servers
- single way to deploy, monitor inference services / server, and scale inference workload
- dramatically shortens time for data scientist to deploy model to production
The project description from their open source github repository:
"KFServing provides a Kubernetes Custom Resource Definition for serving machine learning (ML) models on arbitrary frameworks. It aims to solve production model serving use cases by providing performant, high abstraction interfaces for common ML frameworks like Tensorflow, XGBoost, ScikitLearn, PyTorch, and ONNX. "
Other core features include:
- Pre/Post Custom Transforms
- Outlier Detection
- Canarying
- Concept Drift Detection
- Native Kubernetes Framework
Convolutional Neural Network Explainer
(Paper) CNN Explainer: "Learning Convolutional Neural Networks with Interactive Visualization"
Convolutional Neural Networks (CNNs), while tremendous at certain types of tasks (e.g., "computer vision"), are notoriously hard to understand. The Polo Club of Data Science at Georgia Tech built a live visualization tool to better visually understand CNNs, as shown in the image below.
Team: CNN Explainer was created by Jay Wang, Robert Turko, Omar Shaikh, Haekyu Park, Nilaksh Das, Fred Hohman, Minsuk Kahng, and Polo Chau, which was the result of a research collaboration between Georgia Tech and Oregon State.
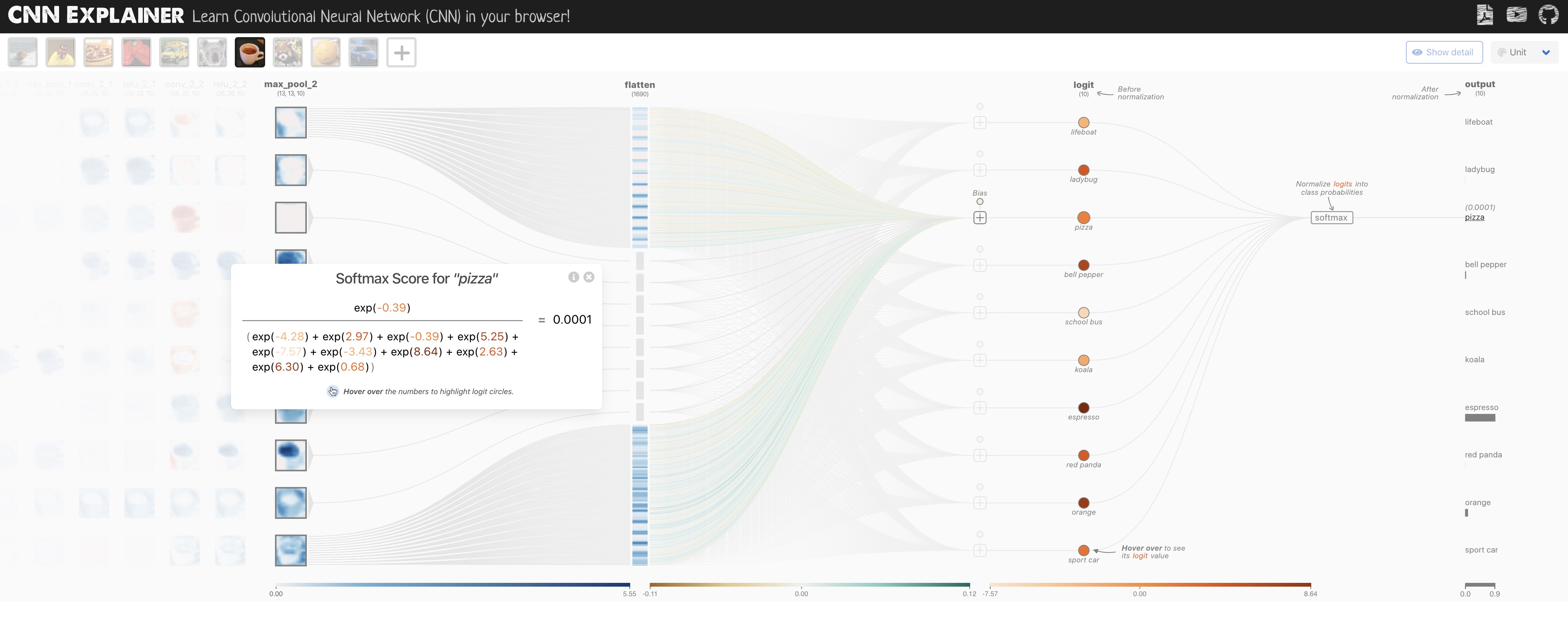
The CNN Explainer live visualization tool in Action).
The video below further shows their UX interacting with a Convolutional Neural Network.
Snorkel
Why is Snorkel compelling?
Obtaining labeled training data is one of the largest practical roadblocks to building machine learning models for use in most industries today. In supervised learning we need labeled data to build models; Neural Networks, for example, need around 10,000 examples per class to general decently well. Many datasets that exist where we can infer the label through log analysis (e.g., "anomaly detection") still have the issue where we have few real examples of the "anomaly" class. In other cases where we have lots of data for all classes we may not have labels for the data. Although there are labeling tools out there, it is still labor and time-intensive to build a quality labeled training dataset in those cases. Enter: Snorkel.
The project description from the website:
"Snorkel is a system for programmatically building and managing training datasets without manual labeling. In Snorkel, users can develop large training datasets in hours or days rather than hand-labeling them over weeks or months."
There are 3 key operations performed in a Snorkel pipeline:
- Labeling data
- Transforming data
- Slicing data
Jeff Dean tweeted about a variation of Snorkel recently as well:
Hand-labeling training data for machine learning problems is effective, but very labor and time intensive. This work explores how to use algorithmic labeling systems relying on other sources of knowledge that can provide many more labels but which are noisy. https://t.co/7N8W4h869X
— Jeff Dean (@🏡) (@JeffDean) March 14, 2019
To better understand how Snorkel is used in practice, take a look at these 3 example use cases:
- Apple's Overton Project using ideas from Snorkel
- Google AI Blog: Harnessing Organizational Knowledge for Machine Learning
- MRI Image Sequence Classification Work: Weakly supervised classification of aortic valve malformations using unlabeled cardiac MRI sequences
Github Actions
Why is this project compelling?
The Github Actions claim to fame is that they allow you to invoke a chatbot natively on GitHub to test your machine learning models on the infrastructure of your choice (GPUs) and log all the results. The system also gives you a rich report back in a pull request so that you and your team can see the results.
With Github Actions you can perform a sequence such as:
- Issue a chat command to GitHub Actions "/run-full-test"
- This would generate a link to a ML Pipeline running the test in the Pull Request (PR)
- The results of the pipeline run (e.g., "model statistics") would be written back into the PR (with links)
- Issue a follow up chat command to deploy the candidate model
- GitHub deploys this mdoel to production, records action in PR
- Detailed logs of the whole process are recorded in the PR as well
"GitHub Actions makes it easy to automate all your software workflows, now with world-class CI/CD. Build, test, and deploy your code right from GitHub. Make code reviews, branch management, and issue triaging work the way you want."
For more information, check out the Official documentation or watch the video below:
Fast Pages
Why is fastpages compelling? Per their website:
"fastpages automates the process of creating blog posts via GitHub Actions, so you don’t have to fuss with conversion scripts. A full list of features can be found on GitHub."
The diagram below is from their website showing the general workflow:

Communicating a story about data is key to the data science workflow result. Fast pages provides a great tool to more quickly generate web-published results about your data science work.
Some of the key features include:
- Easily convert Markdown, Word Documents, and Jupyter Notebooks to HTML pages
- Built-in search
- Support for interactive visualizations in Jupyter Notebooks
openAI's Microscope
OpenAI's Microscope is compelling because it allows us to look at the internals of a Neural Network (similar to the CNN Visualizer Above) with different lens attached; This allows us to view the internals of a network to "see how it hallucinates" under certain input and parameters.
Many times in research observations are made about the internals of a neural network such as how a specific layer or connections between layers produce certain effects (e.g., a high level features like pose-invariant dog detectors in Inception v1, 4b:409). OpenAI's Microscope tool allows the user to visually inspect that section of the network to validate such an assertion. Some of the "lens" included in the tool are "feature visualization", DeepDream, dataset examples (images that causes neurons to fire strongly), and more.
From their website:
"We’re introducing OpenAI Microscope, a collection of visualizations of every significant layer and neuron of eight vision “model organisms” which are often studied in interpretability. Microscope makes it easier to analyze the features that form inside these neural networks, and we hope it will help the research community as we move towards understanding these complicated systems."
The screenshot below shows off some of the visualizations of the tool.

exBERT
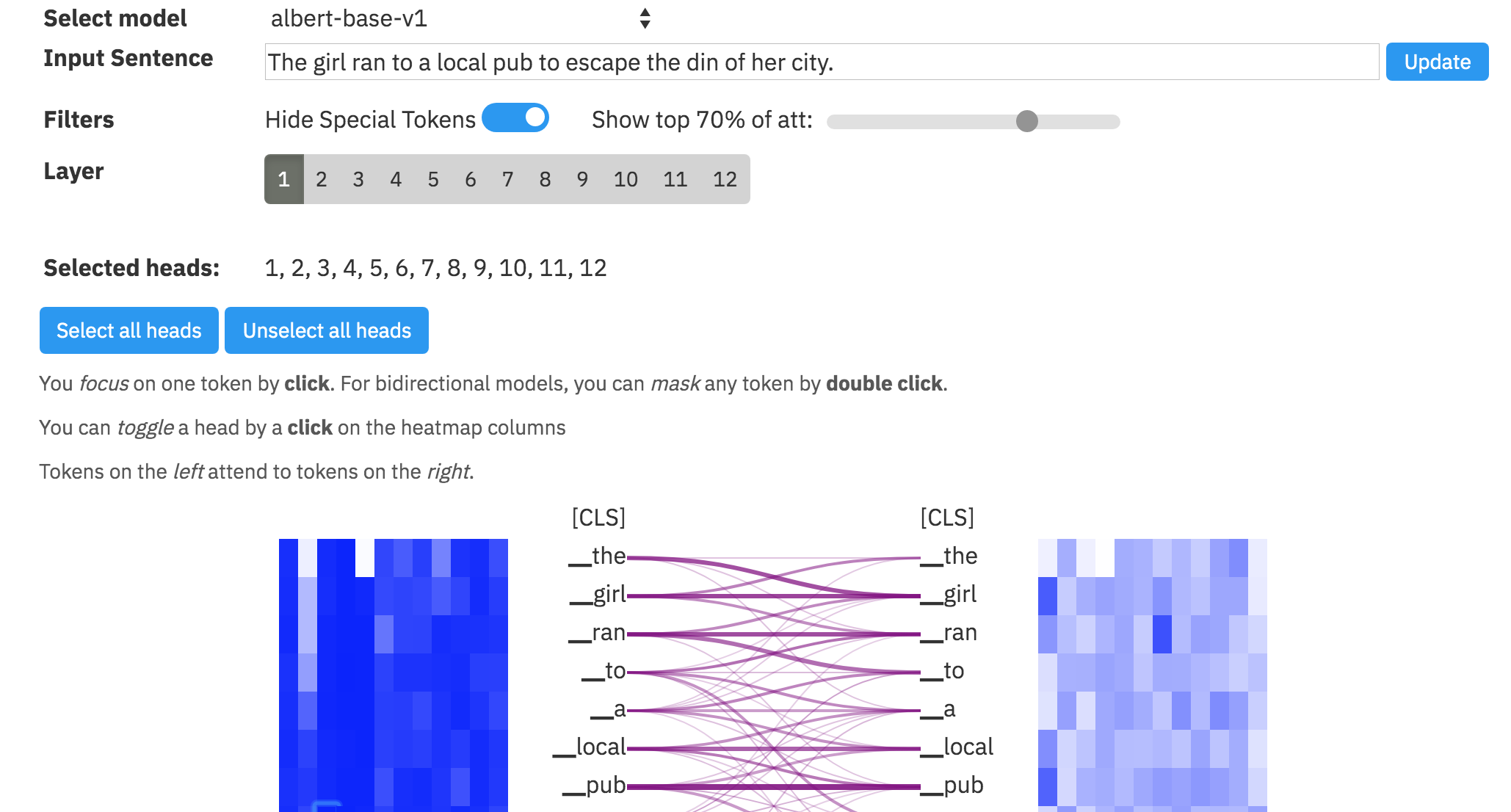
exBert is another interesting visual analysis tool in machine learning, this time focused on the family (BERT, DistilBERT, RoBERTa, XLM) of NLP models. From their website:
"Large Transformer-based language models can route and reshape complex information via their multi-headed attention mechanism. Although the attention never receives explicit supervision, it can exhibit understandable patterns following linguistic or positional information. To further our understanding of the inner workings of these models, we need to analyze both the learned representations and the attentions. To support analysis for a wide variety of 🤗Transformer models, we introduce exBERT, a tool to help humans conduct flexible, interactive investigations and formulate hypotheses for the model-internal reasoning process. exBERT provides insights into the meaning of the contextual representations and attention by matching a human-specified input to similar contexts in large annotated datasets."
The screenshot below shows off some of the visualizations of the tool by just clicking on the tag #exbert on the @huggingface model's page:
Great Expectations

Why is this project compelling?
Great Expectations is a tool for building assertions for data in an effort to reduce data validation issues in machine learning modeling and analytics. Per the website:
"Expectations are assertions for data. They are the workhorse abstraction in Great Expectations, covering all kinds of common data issues..."
Some of the data issues they cover:
- Expect a column to be not null
- Expect a column to match a REGEX pattern
- Expect a column value to be unique
- Expect a column to be match a date time format
- Expect a table row count to be between a range
The project has a philosophy that "tests are docs and docs are tests"; Given that docs are rendered from tests, and tests are run against new data as it arrives, the documentation is always kept up to date.
Great Expectations works with frameworks such as Pandas/Python, Spark, Postgres, BigQuery, tools on AWS, and more.