
The Evolution of Retrieval Augmented Generation
Enhancing LLMs with Private Data to Generate Better Answers
Author: Josh Patterson and Josh Bottum
Date: January 19th 2024
Introduction
In 2023, enterprise CTOs acknowledged that Large Language Models (LLMs) can generate better answers than humans. In 2024, CTOs are expanding their LLM use cases, while carefully navigating the rapidly changing LLM landscape, which now includes LLMs with Retrieval Augmented Generation (RAG). RAG adds tremendous value because it enables LLMs to generate answers with fresh data from internal and external sources. RAG expands the delivery of higher-value applications, especially for use cases that require reasoning, enabling market leaders to materially differentiate their business functions.
RAG gained speed in April 2021 in this seminal paper, “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, which demonstrated that LLMs with RAG performed better than LLMs, and better than humans.
In this article we take a look at “what is retrieval augmented generation?” and “how is retrieval augmented generation’s definition evolving?”.
What is Retrieval Augmented Generation?
Retrieval Augmented Generation is a strategic approach employed to integrate external, user-specific data into the process of generating responses or content with large language models. Unlike traditional LLMs, which rely solely on their training data, RAG allows these models to dynamically fetch relevant information from external sources during the generation phase.
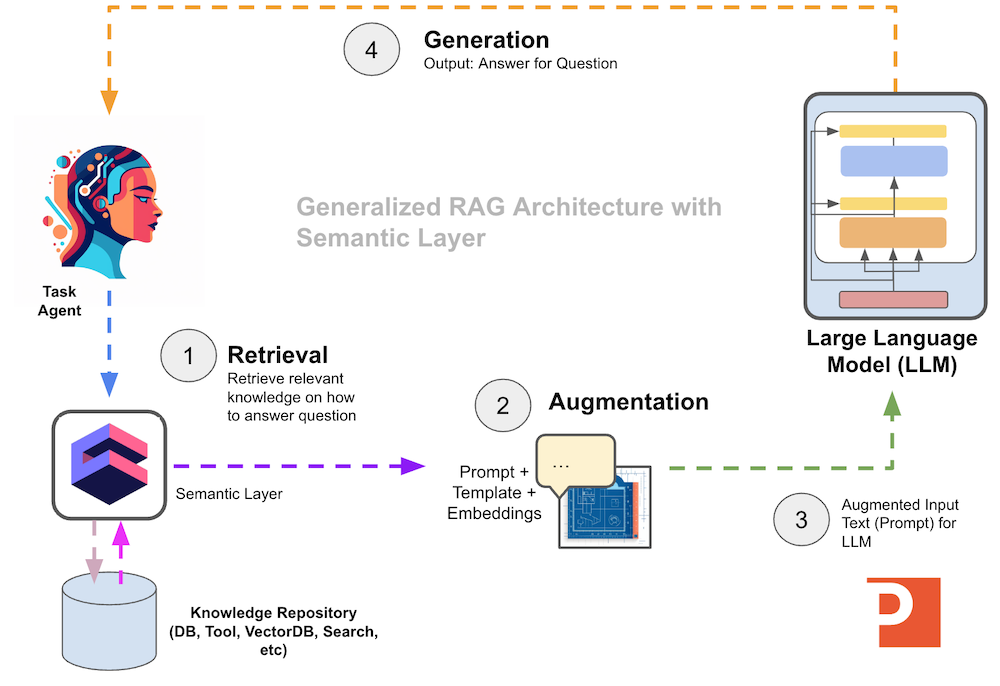
With the architecture of RAG we are seperating the role of knowledge and reasoning (book link). This idea is visually illustrated in the diagram below.
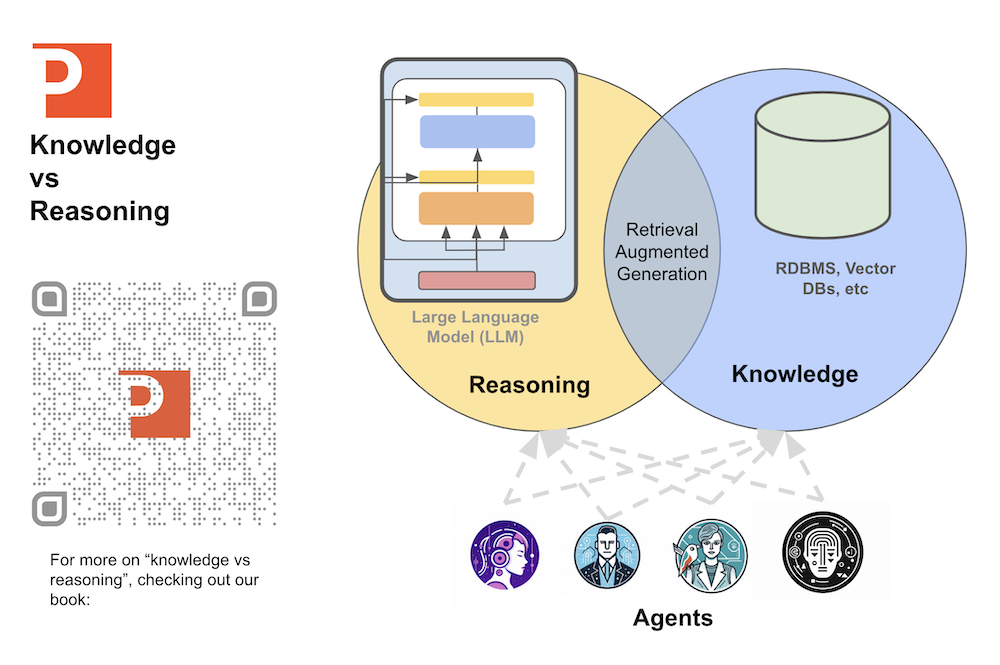
We use the RAG design pattern to connect our private knowledge with the reasoning power of LLMs to build next-generation AI applications. RAG is made up of 3 logical phases:
- Retrieval
- Augmentation
- Generation
We can see a general RAG architecture in the diagram below.
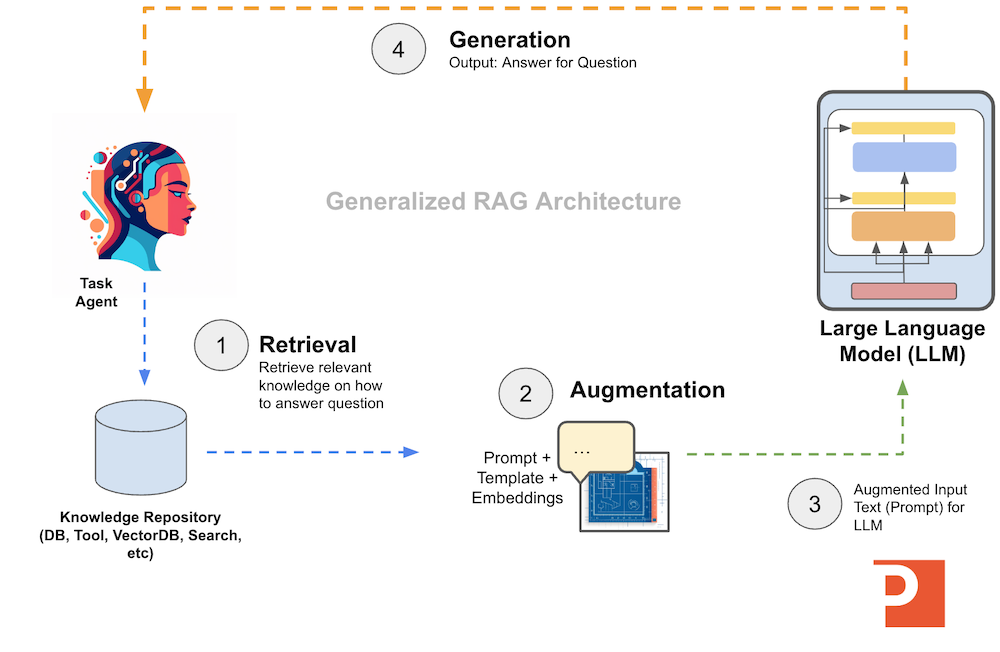
Retrieval
The Retrieval part of “Retrieval Augmented Generation” is focused on gathering data from knowledge systems to use directly inside a prompt (“raw text”) sent to a large language model.
Augmentation
The Augmentation part of “Retrieval Augmented Generation” is how we take the extracted information from a knowledge system and integrate it into prompt or prompt template.
Generation
The Generation part of “Retrieval Augmented Generation” is how we take the combination of the extracted information and the custom prompt and pass it to a large language model for evaluation, reasoning, and response generation.
Why is RAG Important?
RAG provides specific functionality for LLM-based applications such as:
- Enhanced Decision Support:
- End users often deal with complex and rapidly changing business scenarios. RAG empowers LLM applications to provide more nuanced and informed responses by incorporating the latest market trends, industry news, and company-specific data.
- Personalized Communication:
- RAG facilitates personalized communication by considering user-specific information. This is particularly beneficial when addressing individualized queries, making interactions more meaningful and relevant.
- Improved Problem-Solving:
- In dynamic business environments, quick and accurate decision-making is crucial. RAG equips LLMs with the ability to fetch real-time data, aiding managers and VPs in solving problems efficiently.
RAG enables a broader set of applications to be supported because current information is used to deliver logically developed answers with human-like reasoning. Reasoning greatly enhances the value of answers, especially for enterprise applications. LLM reasoning apps are compelling from operational and functional perspectives.
Defining Traditional RAG
During 2023, we saw important investments in RAG and most market leaders published detailed RAG technical reviews. For example, LangChain documented their traditional RAG architecture utilizing a vector store which includes this workflow:

The traditional vector store workflow includes six functions:
Document loaders: Document loaders simplify the loading of different types of documents (HTML, PDF, code) from different locations (private S3 buckets, public websites, private storage).
Text Splitting: Long documents need to be split or chunked into smaller pieces and specialized algorithms transform the data (code, markdown, etc.) into smaller chunks. This enables you to fetch only the relevant parts of documents.
Text embedding models: Text embedding is a process to capture the semantic meaning of the text. This enables you to efficiently find similar chunks.
Vector stores: Vectors stores are databases that store and search embeddings.
Retrievers: Data is retrieved from your vector database using a retrieval algorithm, such as semantic search. Adding these algorithms can increase performance: Parent Document Retriever (returns a larger context from multiple small chunks), Self Query Retriever (selects the semantic part from other metadata filters), and Ensemble Retriever (returns and integrates chunks from multiple documents).
Indexing: An indexing API syncs your data sources with your vector store. Indexing provides more efficient vector store operations by mitigating unnecessary actions on unchanged or duplicate content.
Expanding RAG’s Definition
Contributions in the RAG domain are wide spread. For example, this Microsoft blog provides the following diagram, which demonstrates how RAG and LLM functionality are evolving:

As you can see in the chart above, query - knowledge now replaces the concept of the more specific embeddings and vector databases from the LangChain diagram.
AWS similarly has a blog article that shows the “retrieval” part of RAG as “search relevant information”:

In early 2024, a new paper delivered an extensive analysis of RAG’s evolution, Retrieval-Augmented Generation for Large Language Models: A Survey.
Technically, the paper introduces the Advanced RAG paradigm, extending beyond the naive approach by incorporating sophisticated architectural elements such as query rewriting, chunk reranking, and prompt summarization. It explores hybrid content retrieval with both structured and unstructured data sources (e.g., images, videos, code) and reviews cutting-edge research on self-retrieval from LLMs, including dynamic timing of information retrieval.
The paper also introduces an evaluation framework for RAG models, including benchmark tests and automated evaluation tools providing quantitative metrics. It emphasizes four key abilities indicating a model’s adaptability and efficiency: noise robustness, negative rejection, information integration, and counterfactual robustness. Finally, it underscores the imperative to mature and refine evaluation methodologies.
The generalization of the two cloud RAG architecture diagrams and the 2024 paper show that the idea of Retrieval in RAG is evolving beyond the original “embedding + vector database” concept to include other styles of retrieval.
Advances in Retrieval
We close out this article by discussing some of the ways we’re evolving and expanding the concepts of retrieval augmented generation at Patterson Consulting.
Semantic Data Connectors
A semantic data connector is a connector to a knowledge repository (e.g., “salesforce”, etc), but primarily focuses on using a combination of metadata APIs and LLM calls to reason about what type of data is in the repository, and what type of data it needs to extract. This type of data connector needs good natural language information returned from the API metadata so that it can better reason about what is in the different tables of the repository. It is similar to LangChain’s SQLChain in idea, but has different data structures and different sets of custom prompts for reasoning over the knowledge repository metadata.
Use of Data Catalogs for Dynamic Discovery
Similar to semantic data connectors, we also have experimented with another layer above the connectors: the use of data catalogs, such as Alation’s data catalog, to let systems reason about where the data they need may reside.
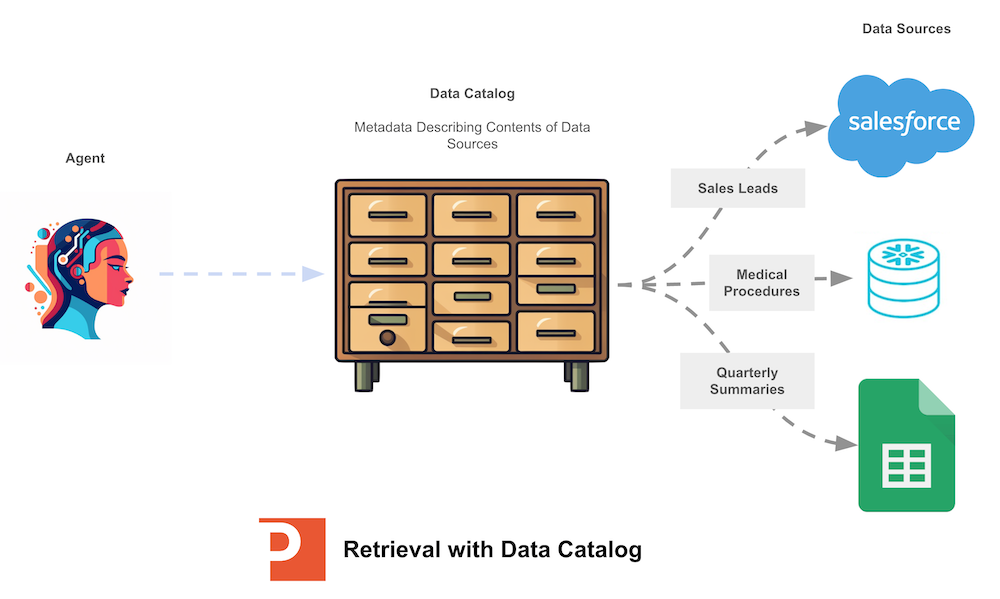
This type of RAG augmentation is a pre-step to retrieval where the system reasons about which data repository it wants to query, and then loads the correct semantic data connector based on the selected data repository type.
Prompt Routing and Multi-Agent Systems
Sometimes we know an application (e.g., “analytics”) will be handling N number of types of requests, and we can use a method called “prompt routing” to branch the execution of our code to a set of sub-agents to handle a specific type of request. This allows the sub-agents in this multi-agent system to focus specifically on an identified task and restrict their prompts to goals associated with this task pipeline.
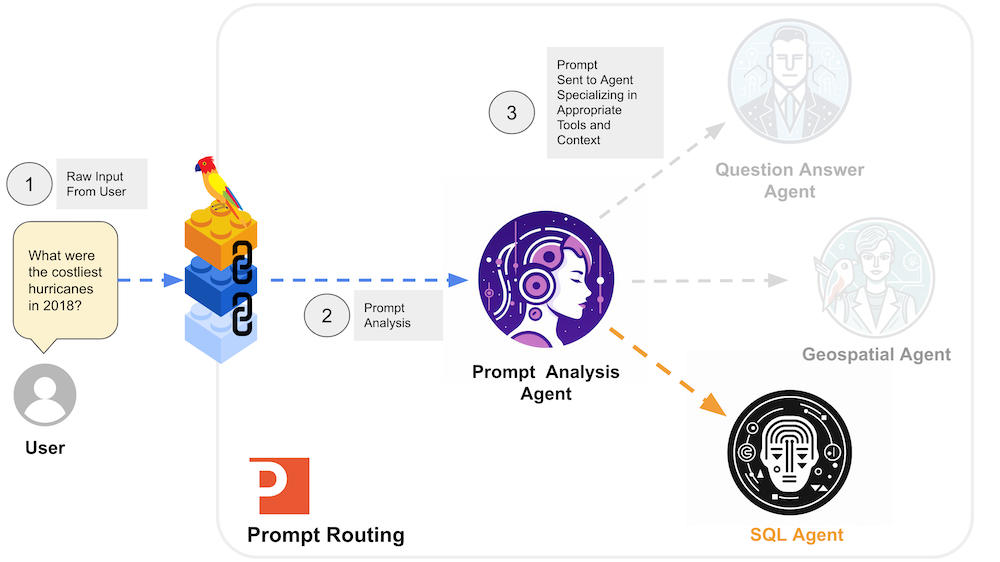
Currently Patterson Consulting uses our own implementation of prompt routing, customized for different scenarios, as part of our Augmented Reasoning library.
LangChain now has functionality similar to this called RunnableBranch.
A Langchain RunnableBranch dynamically directs program flow based on input conditions, enabling non-deterministic step execution. It enhances structure and consistency in LLM interactions, offering routing through a RunnableBranch or custom factory function. The former selects and executes a runnable based on conditions, while the latter returns a runnable without execution based on input from a previous step, implemented via the LangChain Expression Language.
Retrieval Augmented Generation and Semantic Layers
In some situations we want to use llms to generate SQL queries with tools such as LangChain’s SQLChain. In these cases the application performs more consistently when the databases, tables, and columns have metadata that looks more like full natural language as opposed to short-hand words and codes.
In these situations using a semantic layer to provide a more verbose and descriptive set of tags on data models can help improve query generation, as seen in the diagram below.
What is a Semantic Layer?
A semantic layer can improve retrieval performance through
- better user management and security
- better metadata
- better data modeling over canonical tables
A semantic layer is useful for the scenarios where we are using LLMs to select the correct table and then write a good SQL query statement to return the right data for the natural language query.
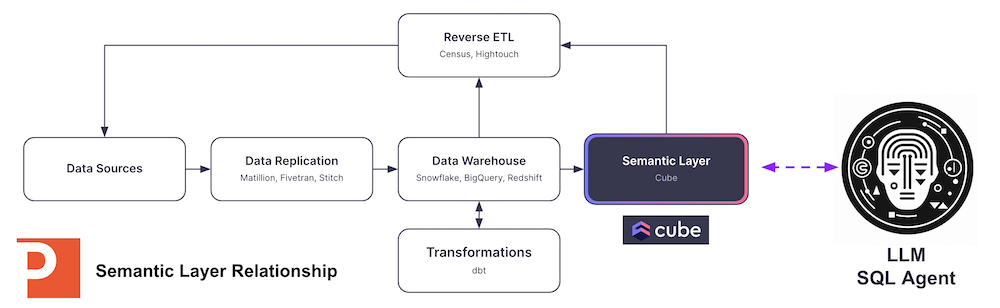
The data modeling provided by a semantic layer is critical to giving the SQL Agent the context it needs to reason about which tables to use to answer the question posed.

When we are able to generate better SQL queries, we can pull more accurate information back for the augmentation phase to better support the generation phase. This gives more consistent and better quality results to the end user.
A great example of this is using a Cube.dev data model over a Snowflake table, exposing the more verbose Cube.dev data model to the LangChain SQLChain tool.
Use of Private LLMs with Retrieval Augmented Generation
As we integrated more of our private information and customer information into LLM-based applications, if we are using LLM models that we do not control (e.g., “openAI”), there exists a scenario where the company who operates the model as an API may change their terms of service and begin training on our private data (or our customer’s private data).
In this scenario you should strongly consider using a private model as your reasoning engine for your retrieval augmented generation architectures.
Advantages include:
- security of sensitive data exposure
- use of specialized models for your domain
- cheaper cost of operation at scale
Summary
In this article we provided a traditional definition of retrieval augmented generation, we looked at the areas where retrieval augmented generation is becoming more broadly defined, and then finally closed with some specific ways Patterson Consulting is developing new ways to improve retrieval augmented generation.
The video below shows our suite of concept applications that we demonstrated at AWS Re:Invent 2023 this year.
If you’d like to know more about how we apply retrieval augmented generation in practice for Enterprise customers, join our webinar with Cube and Quantatec on January 24th.