
A Cloud GPU Value Model for NVIDIA Multi-Instance GPUs (MIG)
Author: Josh Patterson
Date: 5/11/2021
In this post we build a cloud value model for NVIDIA Multi-Instance GPUs (MIG) devices in the context that they can be managed under Kubernetes as "GPUs as a Service" (GaaS), similar to spinning up a GPU instance on AWS.
In previous posts we introduced MIG and how it operates as managed by Kubernetes, demonstrated Forecasting Your AWS GPU Cloud Spend for Deep Learning, and introduced an online AWS GPU Cost Calculator. We continue to further build off these posts to develop our valuation model for the DGX-A100, MIG, and Kubernetes.
Framing Our Valuation
The target audience for this article are the people who run MLOps platforms / infrastructure in enterprise IT organizations. These people (.e.g., "Head of Global Infrastructure"), are interested in optimizing their cloud and on-premise infrastructure spend to get the right balance.
To build our valuation we will:
- Frame the context for valuing the resources
- Create a valuation for a hypothetical single-GPU A100-based AWS instance
- Extrapolate MIG Device values from the single-GPU instance pricing
- Calculate the cloud-value of MLOps software (on the DGX-A100) that would be analogous to SageMaker
Why is this a Compelling Exercise?
Why is this building a valuation of MIG Devices (under Kubernetes) in a DGX-A100 a compelling exercise?
Many times in customer discussions the question "how does X system's cost compare to a similar, apples-to-apples, system's TCO in the cloud?" come up. This series of blog posts seek to answer questions we get during customer conversations, or share generalized notes from past discussions. This post is intended to inform you on when where both cloud and on-premise GPUs (e.g., DGX-A100) are a better fit for your needs.
There is a lot of compute-dense hardware and a lot of different types of workloads, on-premise and in the cloud. Understanding the cost model for what a user in a multi-tenant system is consuming (in terms of resources) is valuable when comparing Total Cost of Ownership of on-premise infrastructure with cloud infrastructure.
GPU hardware is getting bigger and faster, but the need to dedicate a single GPU to a single user or task is hitting the headwinds of heterogenous workloads in the enterprise. Allowing a CPU to be shared amongst multiple processes is not a new concept and as GPUs become more general purpose they are gaining similar capabilities via NVIDIA's MIG technology (in the A100 line of GPUs).
In the realm of shared infrastructure, efficiency is key and Kubernetes helps maximize resource usage. Allowing a full A100 GPU to be shared across multiple workloads with MIG and then all of these partitioned MIG resources to be managed by Kubernetes helps maximize efficiency and utilization in a data center. Topics such as these are common amongst MLOps engineers today.
MLOps is More Than Just GPUs
MLOps in practice involves more than GPUs and hardware. The context of our evaluation of MIG's value compared to the cloud is as part of a machine learning platform. From that point of view, we define our machine learning platform as:
- compute hardware; here, GPUs and GPU memory
- multi-tenant resource management and container orchestration; here: kubernetes
- MLOps Platform: 3 common ones we see are SageMaker (AWS), Kubeflow (DGX), and MLFlow (local)
The function of MIG is to provide more compute surface area from a finite amount of compute hardware (e.g., the DGX-A100). In this way MIG is creating potentially many more GPU "compute slots" than physically are available as single GPUs in the host. This is a good feature for organizations wanting to provide GPU computing power for a large pool of data scientists.
From that perspective we are focused on mapping our pricing model based on how a group of data scientists would use a pool of GPU instances on AWS.
MLOps Questions?
Are you looking for a comparison of different MLOps platforms? Or maybe you just want to discuss the pros and cons of operating a ML platform on the cloud vs on-premise? Sign up for our free MLOps Briefing -- its completely free and you can bring your own questions or set the agenda.
How are GPUs Used Today by Data Scientists?
We're building a value model based on cloud GPU resources so we'll consider this quesiton from the perspective of a team operating on AWS. Today a data science user (on the cloud) typically wants to:
- spin up an GPU/EC2 instance quickly, do their work, and then (hopefully) shut it down
- most of the time this will involve an EC2 instance with a single gpu
- to do this quickly, they'll likely have their python code saved as a container
A Cloud Value Model for MIG Devices on the DGX-A100
Based on the usage patterns from the previous section, we are looking to base our price analysis around a pool of instances each with a single GPU.
With this in mind we now seek to build a valuation of a hypothetical instance with a single A100 GPU attached. We already know the rough translations of the power of different MIG Device profiles, so once we have the single instance A100 GPU price, we can divide the price by the comparable fraction of resources it provides (or the most comparable cloud GPU instance price for those resources).
Forecasting the Value of a single A100 GPU-instance on AWS
Why GPU Compute Power is a Unique Driver of Value
Other resources on public cloud have value beyond the compute power of the instance such as:
- reliability
- durability
- fail-over
- ...more...
By using a GPU we don't buy better accuracy, we shorten our training time, allowing us to try more variations and find better solutions/models. Therefore, value in the space of cloud GPUs is directly tied to GPU relative power. E.g., I can use any GPU instance I want on AWS, but some instances will train the same model in a shorter amount of time. I am trading money for time in this case, so it makes sense to view cloud GPUs in a relative compute power sense and then compare that to the difference in price.
There are a lot of ways to estimate what the value of an A100 GPU-based instance should be, but we wanted to visually take a look at how the price and performance has changed across progressively more powerful GPU-instances offered on AWS. If our pricing model is decent, our forecasted price of the A100 single-GPU instance will "visually" fall in line with the trajectories of the other instances on AWS.
To create these visual trajectories, we based our calculations on the power and price of the K80 GPU chip (AWS p2 instance) so that we can see the relative trends in price and performance.
In the graph below we can see two series:
- The speedup multiple of major GPU-type compared to the K80 GPU
- The price multiple of the same GPUs compared to the K80 GPU
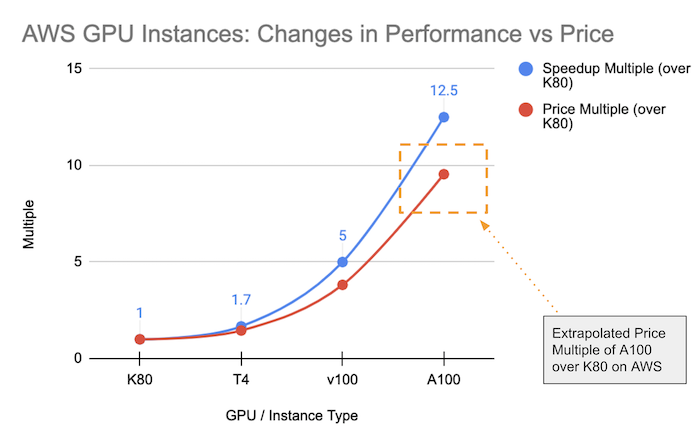
We also have collected notes that give us relative computation power comparisons between the 4 GPUs ("Speedup Multiple (over K80)"), as you can see represented by the blue series in the graph above.
We can also visually see how the price changes across the same 3 GPU-instances on AWS and then where the forecasted A100-instance multiple should land. The A100-hypothetical instance price multiple is extrapolated based on how the price was changing vs how the performance was changing. Based on the trajectory of both trends, the price multiple (over the K80) should "visually land somewhere in the orange box area". We derived this multiple to be 9.5x the price of the K80 instance on AWS.
We also want to note that we feel this A100 price multiple (9.5x) over the K80 "feels right" because if it were lower it would start to canabalize the sales of the V100-based p3 instances (e.g., "why get a V100 when I can get a A100 for nearly the same price?"). If the price multiple were higher then it would incentivize users to fall back to a better deal with the V100-based p3.2xl instances.
GPU Power vs Value Trend
Before we move on, we want to note that for AWS GPU instances it appears that as the GPUs get more powerful, you get more "compute value" for the same dollar (e.g., the speedup multiple is increasing faster than the price multiple).
This trend suggests more powerful gpus are better value on AWS.
Wait a Minute -- Doesn't AWS Already have an A100-based Instance?
The short answer is "yes"
This leads us to ask:
Why not assign value of a MIG device based off the existing p4d.24xlarge instance?
Now, the longer answer:
The p4d.24xlarge does offer A100 GPUs, but it offers 8 of them in a single instance. While this instance type gives us the same core GPU, it is not in a form factor that a data scientist using a MIG device for computation would actually be using in practice.
As a user I'm probably not going to do this because the economics don't work for my use case (and I'd have to write my code to be able to use multiple-GPUs, which can be non-trivial in some cases). Therefore, the p4 instance does not fit our valuation model (and we'll address this further in a moment).

Trying to Manage a p4d.24xlarge Instance with MIG and EKS
It is technically possibly to manage a p4d.24xlarge instance on AWS with MIG and EKS. However, this is non-trivial to stand up and would require a tricky install along with integration with an MLOps platform. This combination of factors is likely going to be beyond what most IT departments want to take on in terms of system management overhead.
Companies use the cloud for flexibility and to offload their IT overhead. Users don't want to get tangled up into system management and just want "self-service GPUs". From this perspective, we set aside the value comparison of a single p4d.24xlarge instance because it does not fit in our valuation model.
Now Let's Translate the Single-A100 Price Multiple Into a Price
AWS does not offer a single A100 card GPU instance so we have to extrapolate what that would cost if it did exist based on other GPU instance prices on AWS that offer single GPUs.
To calculate the forecasted price of the single-A100 GPU instance we take the blended (average of the on-demand and 1-yr reserve) price of the K80 p2 instance ($0.66 / hr) and multiply it by the price multiple factor (9.5x) to get an A100-instance price of $6.33 / hr.
A good quick back of the envelope check on this price is to multiply the 2.5x performance multiple of the A100 over the V100 GPU (in a p3.2xlarge) by the price of the p3.2xlarge instance. This gives us: 2.5 x $2.53/hr == $6.31/hr, only 2 cents off our 9.5x multiple projection.
At this point we have a hourly value for the hypothetical AWS A100-based GPU instance that should hold up based on our calculations and the constraints of the pricing of the adjacent GPU-instances. Let's now move on and build a valuation of a pool of DGX-A100-based MIG devices managed by Kubernetes.
Extrapolating MIG Device Value from AWS GPU Pricing
To build out valuations for the remaining MIG Device profiles we take the $6.33 / hr price for the 7g.40gb full A100 GPU instance and then subdivide this price based on the fraction of resources the MIG Device profile gets, as seen in the table below.
| MIG Device Type | Equivalent GPU | Workload Match | Cloud Value ($/Hr) | MLOps + GPU Cloud Value ($/Hr) |
|---|---|---|---|---|
7g.40gb |
A100 | heavier deep learning training jobs | $6.33 |
$8.86 |
4g.20gb |
$3.62 |
$5.06 |
||
3g.20gb |
V100 (+4GB RAM) | medium machine learning training jobs (Kaggle-type notebooks) | $2.71 |
$3.80 |
2g.10gb |
$1.81 |
$2.53 |
||
1g.5gb |
T4 | Inference (batch-1) workloads (low-latency models), development Jupyter notebooks | $0.90 |
$1.27 |
With MIG (managed with Kubernetes) we can offer a single A100 GPU-based MIG Device (e.g., "Container-based compute instance running on Kubernetes with access to the local DGX hardware") with 40GB of GPU RAM (MIG Profile: 7g.40gb, or 80GB per GPU for a 7g.80gb if you have the 640GB GPU RAM version of the DGX-A100) that is roughly 2.5x times as powerful as a V100 card. Each DGX-A100 provides 8 x A100 GPUs and these GPUs can be sliced up in different ways, providing up to 56 individual MIG Devices from a single DGX-A100.
The MIG Device types (4g.20gb, 2g.10gb) between the 3 listed above allow for further flexibility for workloads that "don't exactly fit in one of the buckets". (see also: Resource Requirements for Different Types of Deep Learning Workflows).
So depending on how we slice up our DGX-A100, that means a single DGX-A100 could be configured to offer up to 56 individual 1g.10gb-based Kubernetes-managed "compute slots". Each of these 56 "compute slots" are roughly equivalent to a g4 instance on AWS, for reference.
No matter how we slice an A100 GPU up with MIG to create combinations of MIG Devices, we can easily look up the corresponding value in the chart above. Now let's move on to understanding the last column "MLOps + GPU Cloud Value".
Valuing the A100 GPU When Used with a Machine Learning Platform
If we're just using a p3.2xl (for example) AWS instance and running some python machine learning code in a container on it, we're leveraging "GPUs as a Service" (GaaS).
If you use a DGX-A100 with MIG where the MIG Devices are managed by Kubernetes, then we can launch containers with machine learning code via kubectl similarly to how we'd use an AWS p3.2xl instance. In this way, the DGX-A100 with MIG and Kubernetes can provide multi-tenant shared "GPUs as a Service" (GaaS) similar to how the cloud offers GPUs as a service with equivalently powered instances.
Given that the DGX-A100 with MIG and a MLOps platform (e.g., Kubeflow, etc) offers Jupyter notebook servers and model hosting functionality, we further compute the hourly cost of a “cloud GPU compute instance” with the AWS SageMaker cost multiple of 1.4x to give us a final "MLOps + GPU Cloud Value" of $8.84 for the full 7g.40gb MIG Device running on the MLOps platform. We similarly prorate each of the MIG Device profiles for the rest of the "MLOps + GPU Cloud Value" column.
Summary and Next Steps
In this article we gave a breakdown of how the DGX-A100 with MIG and Kubernetes compared to similar Cloud GPU resources.
If you'd like to know more about how you can use the DGX-A100 with MIG and Kubeflow, check out our AI Accelerator Package with ePlus and NVIDIA. It can help your organization save up to 85% on its cloud GPU bill -- check out the AI Accelerator Package homepage to download the cost study eBook.
Did you like the article? Do you think we are making a poor estimation somewhere in our calculations? Reach out and tell us.
If you'd like to know more about MLOps in general and Kubeflow, check out our latest book with O'Reilly, "Kubeflow Operations Guide".
If you want to run a quick variation on your AWS Cloud GPU costs, check out our online GPU cost calculator.

MLOps Questions?
Are you looking for a comparison of different MLOps platforms? Or maybe you just want to discuss the pros and cons of operating a ML platform on the cloud vs on-premise? Sign up for our free MLOps Briefing -- its completely free and you can bring your own questions or set the agenda.